Mungkin ada sebagian dari kalian yang pernah mendengar tentang clustering ataupun classification tapi sampai detik ini masih belum terlalu paham apa maksud dari kedua jargon tersebut.
Tenang saja, kalian tidak sendirian.
Saya juga pada awalnya bingung dengan kedua topik tersebut. Hal yang membuat saya bingung adalah apa sih sebenarnya perbedaan dan kegunaan dari masing-masing jargon itu. Terutama dalam bidang machine learning, kedua topik ini kelihatannya hampir sama.
Namun setelah dipelajari lebih teliti lagi, ternyata clustering dan classification itu sangatlah berbeda.

Clustering
Di sekolah saya dulu ada yang namanya sistem pembagian kelas berdasarkan nilai rapor. Jadi, kalau murid yang nilainya di atas 85 dia bakal masuk ke kelas A (perkumpulan orang-orang pinter), kalau nilainya di bawah 85 dia masuk ke kelas B, kalau di bawah 70 masuk kelas C, dan seterusnya.
Jadi, bisa dibilang sistem pembagian kelas berdasarkan nilai itu sama halnya seperti metode clustering, hanya saja dalam clustering kita tidak sekedar melihat nilai rapor sebagai parameter melainkan kita juga punya variabel-variabel lainnya yang bisa dijadikan parameter/rujukan untuk membentuk suatu klaster.
Makin bingung? 😄
Gini, misalkan aja kita sebagai kepala sekolah SMP Keripik Kentang 90 pengin buat sistem pembagian kelas supaya anak-anak yang pinter bisa bersaing dengan kelasnya yang sesama pinter.
Tapi di sini kita gak mau bagi tiap kelasnya hanya berdasarkan nilai rapor, karena kita pengin yang ribet (biar antimainstream), kita akan bagi tiap kelasnya berdasarkan 4 faktor atau variabel, yaitu: nilai rapor, jarak rumah dari sekolah, tahun lahir (si kepsek pengin mastiin sio) dan penghasilan orang tua.
Contoh tabelnya seperti ini:
| Nilai Rapor | Jarak Rumah-Sekolah | Tanggal Lahir | Penghasilan Orang Tua |
|---|---|---|---|
| 85 | 2.3 | 2003 | 3000000 |
| 80 | 3.0 | 2003 | 2900000 |
| 75 | 2.0 | 2004 | 3500000 |
Nah, dari data di atas itu kita akan bagi setiap anak ke dalam kelas yang sesuai.
Bagaimana caranya? Pake tongkat sihir Heri Poter.

Tentu saja pakai rumus! Biasanya biar lebih keren, kita sebutnya algoritma.
Algoritmanya apa? Banyak! Ada K-Means, DBSCAN, Mean-Shift, OPTICS, Affinity Propagation, Spectral Clustering, Mixture of Gaussians, dll.
Aduh algoritmanya banyak banget dah, bikin pusing aja.
Nih bentuk rumusnya, biar makin pusing. 😂
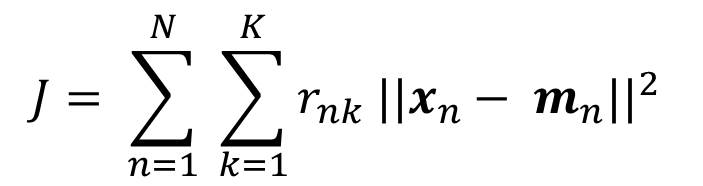 (K-Means Formula)
(K-Means Formula)
Lewat salah satu algoritma di atas, kita bisa tentuin tuh murid mana yang masuk ke kelas A, B, C, D, dst. Caranya yah setiap data di tabel itu dimasukkin ke dalam rumus dan dihitung buat cari persamaan, similaritas, jarak, dan lain-lainnya yang bisa dijadikan validasi untuk sebuah klaster itu terbentuk.
Bentuk tabelnya nanti jadi seperti ini:
| Nilai Rapor | Jarak Rumah-Sekolah | Tanggal Lahir | Penghasilan Orang Tua | Kelas |
|---|---|---|---|---|
| 85 | 2.3 | 2003 | 3000000 | A |
| 80 | 3.0 | 2003 | 2900000 | B |
| 75 | 2.0 | 2004 | 3500000 | B |
Kalau divisualisasikan, clustering itu bentuknya akan jadi seperti ini:
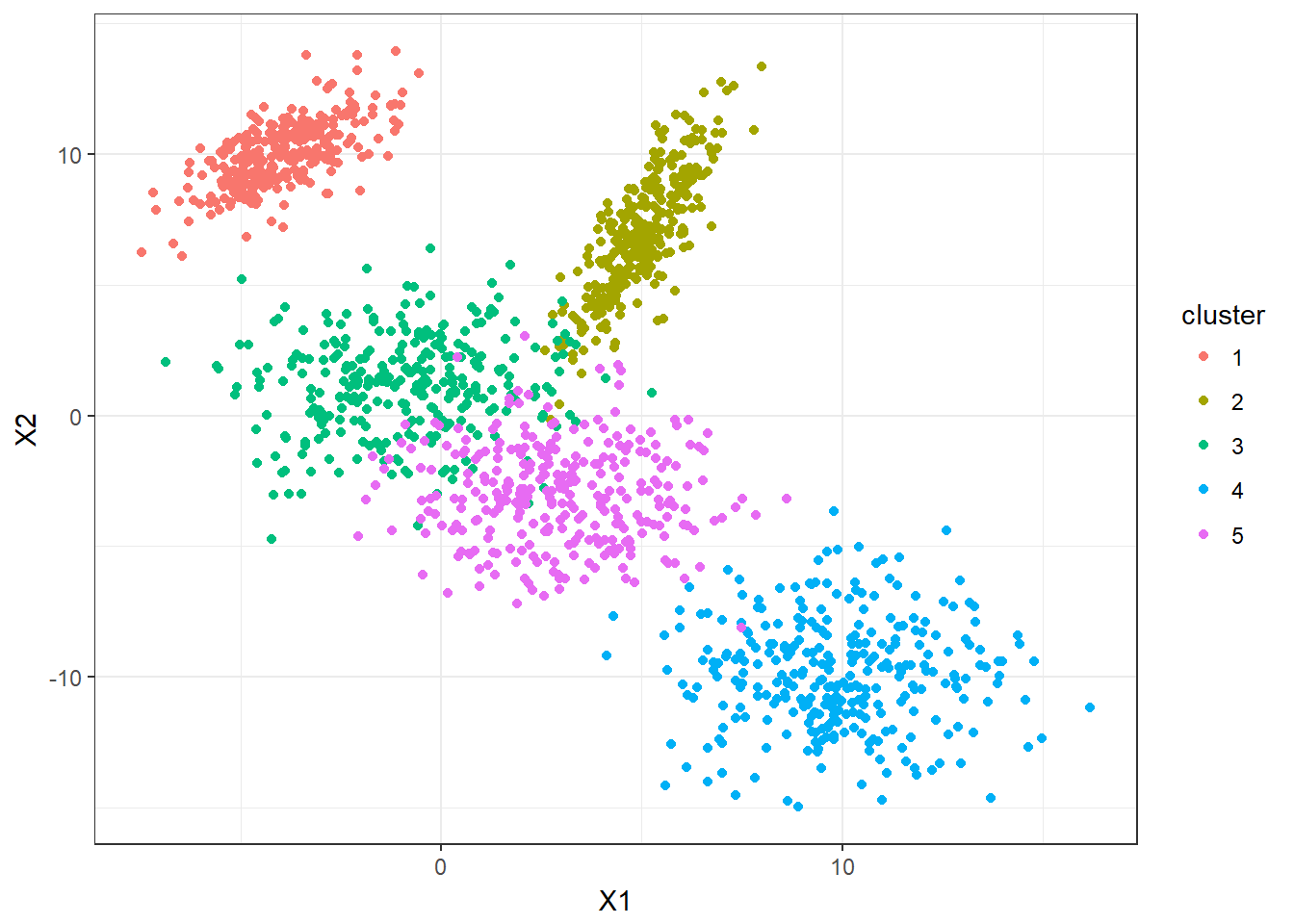
Nah tuh, kelihatan kan ada yang warna merah, orens, hijau, ungu dan biru. Setiap warna merepresentasikan klasternya masing-masing.
Satu hal yang kamu perlu ketahui dan ingat adalah metode *clustering itu datanya tidak punya label*. Maksudnya apa? Maksudnya, lihat tuh tabel pertama kita tadi hanya punya 4 faktor tanpa ada kolom ‘Kelas’ jadi selain untuk membuat klasterisasi atau kelompok-kelompok, metode clustering juga berguna untuk membuat label, seperti pada tabel kedua di mana dari 4 faktor itu setiap data sudah ada labelnya (kelas A, B, C, dst).
Makanya, clustering juga disebut sebagai metode unsupervised learning di mana data inputannya tanpa ada label/kategori/kelas.
Classification
Nah, mumpung masih seger ingatannya. Kalau tadi clustering kan data inputannya tidak ada label/kategori/kelas. Hanya faktor-faktor saja (biasanya kita sebutnya atribut).
Kalau di classification data inputannya itu malah ada label/kategori/kelasnya atau juga disebut sebagai supervised learning. Iya, classification ini memang bertolak belakang sama clustering (kayak Sasuke dan Naruto).

Lalu kalian bertanya dalam hati: lah kalo udah ada labelnya terus ngapain lagi diklasifikasi? napa gak pake countif di excel aja dah?
Tidak secepat itu, Ferguso. 🤣
Kegunaan metode classification bukan untuk mengklasifikasi data inputan yang ada saat ini, melainkan untuk mengklasifikasi data baru yang mungkin akan tercipta di masa mendatang.
Saya tahu kamu pasti bingung, tidak perlu bohong. 😄
Jadi gini, misalkan aja kamu sekarang adalah seorang dokter jantung (sebelumnya kepsek). Lalu kamu ingin memprediksi apakah seseorang (entah itu siapa) punya penyakit jantung lewat riwayat data pasien-pasien yang ada. Riwayat datanya seperti:
| Umur | Gender | Tekanan Darah | Level Sakit di Bagian Dada | Penyakit Jantung |
|---|---|---|---|---|
| 65 | M | 120 | 5 | YES |
| 70 | F | 145 | 3 | NO |
| 70 | F | 135 | 5 | NO |
| 60 | M | 130 | 5 | YES |
Dari tabel di atas bisa kelihatan kan kalau data tersebut sudah ada labelnya, yaitu kolom Penyakit Jantung. Labelnya ada dua kategori, YES dan NO biasa ini disebut sebagai binary classification karena hanya terdiri dari dua output.
Lewat data tersebut kamu ingin memprediksi apakah seseorang punya penyakit jantung jika dia punya beberapa faktor sebagai berikut:
| Umur | Gender | Tekanan Darah | Level Sakit di Bagian Dada |
|---|---|---|---|
| 50 | F | 135 | 7 |
Ini yang tadi saya sebut sebagai data yang akan tercipta dari masa depan. Ngerti kan sekarang?
Lalu cara prediksinya bagaimana? Pake cocoklogi. Ya tentu saja enggaklah, masa penyakit jantung diagnosanya pake cocoklogi sih. Hehehe.
Pertama kita harus buat dulu model machine learning kita menggunakan data yang sudah ada labelnya. Ibaratnya di sini kita mau bikin mesin robot canggih yang nantinya bakal bisa prediksiin diagnosa penyakit jantung seseorang.
Membuat model classfication bisa menggunakan beberapa algoritma, seperti Naive Bayes, KNN, Random Forest, Decision Tree, SVM, ANN, dsb. Kita harus tahu algoritma mana yang cocok sesuai dengan data dan studi kasus kita.
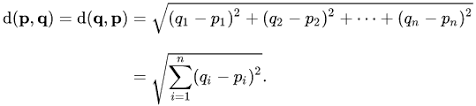 (KNN Formula)
(KNN Formula)
Lihat rumus (yang bikin pusing) di atas itu? Nah, lewat rumus itu kita bakal hitung data riwayat pasien yang kita punya untuk dicari similaritas, persamaan, bla, bla, bla. Intinya mesin robot yang kita buat bakal cari pola-pola tertentu dalam data tersebut, dia juga bakal pelajari bagaimana sih labelnya bisa terbentuk, apakah ada persamaan terkait data 1 dan data 2 dan data-data lainnya dalam tabel (dataset) tersebut.
Setelah model jadi, sekarang tinggal tahapan prediksi di mana kita memasukkan data pasien baru yang ingin kita prediksi apakah punya diagnosa penyakit jantung atau tidak.
Selanjutnya, selesai.
Iya sudah selesai, emang mau ngapain lagi. Klasifikasi udah sampai di situ aja. Sebenarnya prosesnya tidak secepat itu sih, pada praktek nyatanya kita perlu untuk melakukan preparasi data, prosesing data, membagi data ke dalam train dan test, membuat model, mengevaluasi model; menghitung akurasi dll, nah baru terakhir bisa buat prediksi.
Untuk penjelasan lebih lengkapnya dan terperinci mengenai metode classification, kamu bisa baca di sini: https://towardsdatascience.com/machine-learning-classifiers-a5cc4e1b0623
Kesimpulan
Apa yang sudah kita pelajari dari penjelasan di atas?
- Clustering merupakan metode unsupervised learning, di mana data inputannya tidak memiliki label.
- Classification merupakan metode supervised learning di mana data inputannnya memiliki label.
- Clustering bertujuan untuk mengelompokkan data yang memiliki similaritas/persamaan berdasarkan atribut-atributnya (faktor-faktor).
- Classification bukan untuk mengklasifikasi data inputan yang sudah ada, melainkan membuat model dari data inputan yang ada untuk kemudian dipakai untuk memprediksi data yang belum ada labelnya.
- Clustering membuat kelompok-kelompok label, classification membuat prediksi terhadap label.